Semantic approach to training ML data sets using ontologies & not Sherlock Holmes
In this blog we discusses how Sherlock Holmes (amongst others) made an appearance when we looked to exploit the efforts of Wikipedia to identify articles relevant to the life science domain for a language model project.

We explain how the semantic approach to using ontologies is essential in successfully training machine learning data sets.
Princess Bubblegum, Leonard McCoy, and Noah’s Ark have all caused me problems over the last few days. Similarly, Peruvian folk music. And not forgetting Sherlock Holmes – the latter, specifically because of his use of cocaine.
Semantics underlies the work we do everyday at SciBite. The ontologies we use help us to mean what we say, and have an artifact to record and share that meaning. Attaching this meaning to data is very useful – it helps us to find with more precision the data our customers really need, reducing the noise and cleaning up the data.
When we want a broader search, it helps us expand our horizons. Being able to say ‘all parts of brain’ for instance, rather than having to think of and list all of the parts individually, is extremely useful.
Extracting the Life Sciences subset from Wikipedia for Machine Learning
In recent days, we have been extracting a large subset of Wikipedia around life sciences for some machine learning work we’re undertaking. A lot of the effort involved in machine learning work is in generating relevant and representative training and test sets. In our case we were looking to exploit the efforts of Wikipedia to identify articles relevant to the life science domain for a language model we were creating.
Clearly, manually sifting through the 5.8 million articles in English Wikipedia to extract the life sciences subset, which is our goal, is totally unfeasible. Instead, we tried a more semantic approach.
Wikipedia contains ‘categories’ to which each article is assigned one or more. It is a way of being able to group similar articles together such that if you were, let’s say looking for any article on ‘streets in Kathmandu’, you could find them, shown in the image below.

This is not dissimilar to how we, in the life sciences community use ontology classes. Ontologies allow us to group together similar concepts, such as brain parts or possible subspecies of mice, such as below.

Our intuition then was to lend our normal approaches, following the ontology (category) tree from top level categories down to the lower ‘leaf’ nodes and extract all articles tagged with these categories. And it mostly works pretty well. See below a bit of the ontology of Wikipedia we extracted along the way as we built out our machine learning model.
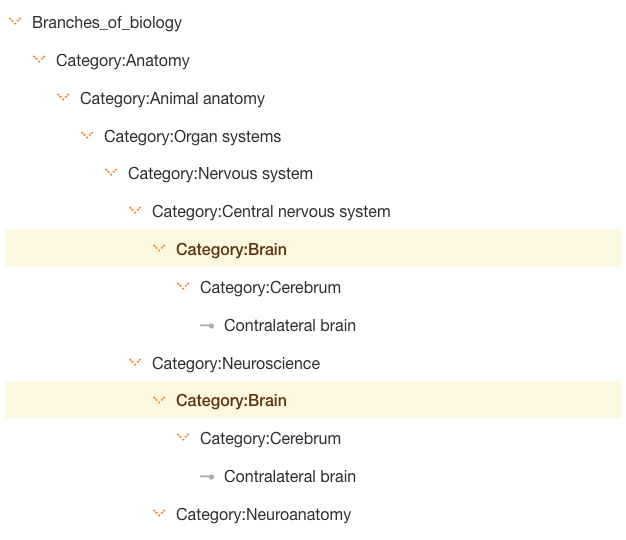
Weaker semantics vs stronger semantics
One issue that quickly emerges from this approach is that in using the ‘weak semantics’ of these Wikipedia categories as a proxy for ‘stronger semantics’ such as those found in ontologies we over-commit to their meaning. The weak semantics Wikipedia uses is a SKOS like organisation which points upwards and downwards from a concept to indicate it more generally in some way or that it is a more narrow grouping. For instance, in SKOS it is perfectly legitimate to say that a person is a more narrow grouping than a village, and that a village is a more narrow grouping than a country. There is clearly no inheritance here; what is true of the broader thing (i.e. the country) does not have to be true of the narrower thing (i.e. the person) but there is a directional grouping. But the specific meaning is implicit only.
In an ontology the super/sub class relationship is a critical, explicit component. What is true for a given class is also true of all its subclasses. We utilise this all the time in our hierarchies. Apoptosis is a subclass of cellular process, Alzheimer’s disease is a subclass of central nervous system disease, and so on.
So what happens when we rely on weaker semantics? As the meaning is not explicit, things get a bit noisy. In essence the bundling of the relationship meaning into one very broad, single connection means we have to be very careful in how we interpret these connections.
Take a look at the path from life sciences, as seen in our ontology management platform CENtree.

First levels look reasonable as we traverse down biology.

Things start to get interesting as we head down the Category of Hearing.
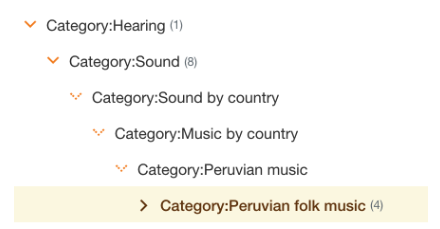
‘Hearing’ leads us to ‘sound’ as a subcategory and at this point we are into a whole new section of Wikipedia – music by country – every country. Including, for instance, Peruvian folk music.
Then what about Sherlock Holmes, how did he make our cut of the life sciences slice of Wikipedia? Let’s look at the subcategories that get us there.

As you can see the subcategory of cocaine which is certainly relevant in a life sciences domain, leads us to a class of “Fictional cocaine users”, whereby we end up in some odd articles (look away now children!).
We also have other fictional categories, such as Fictional life scientists as a subcategory of life sciences. Probably some names you might recognise, below, such as our friend Princess Bubblegum.

Finally, Noah’s Ark. Longevity of life is certainly of interest, but perhaps not in the way it is categorised in Wikipedia.

What did we learn by extracting the Life Sciences training data from Wikipedia?
So took away three learnings from this work. The first, most obvious one, is that Wikipedia ‘life sciences’ category is, somewhat surprisingly, not a good starting place for subcategories on ‘real’ science. The paths that we end up following become too broad and irrelevant, and worse than that, contain fictional subcategories.
The second lesson, is that we can not rely on the weaker semantics of ‘subcategory’ to transitively crawl Wikipedia articles. Articles that are clearly fictional are by definition not science, so are not subcategories of science. One useful addition in Wikipedia would be metadata attached specifically to categories or articles that are fictional in nature so they can be easily filtered out. The fictional characters part of Wikipedia is an ancestor class some way up the category tree for many of the fictional scientists mentioned, but this also relies on the semantics of the ‘subcategory’ used in Wikipedia, which, as we have discussed, is not semantically clear. So we are somewhat caught between not relying on subcategories for science, but relying on them for fiction subcategories. Minimally, it weakens the use of Wikipedia as a computationally amenable resource (not to diminish, of course, it’s incredible value as a human readable website).
The third lesson is that this form of categorisation appears more a process of evolution than design. It teaches us that building large, collaborative categorisations – ontologies or other – is hard and complicated. Things that would help – stricter rules on what a subcategory is and is not. In addition, making the relationships between categories more explicit would help, especially in creating other sorts of relationships between categories. Having a subcategory and a ‘see also’ type relationship would probably suffice, as long as the subcategory was used more strictly, and the ‘see also’ much more loosely.
Either way, the work has made for some really interesting machine learning models should we ever need to investigate connections between the Daleks, Tibetan music, and the Eurovision Song Contest.
Find out more about how ontologies and machine learning work together in our use case.
Learn more about our ontology management platform CENtree.
Related articles
-
How the use of Machine Learning can augment adverse event detection
When it comes to identifying adverse events (AEs), things are not always as they seem. Consider a paper describing a new treatment for a given illness - how can we determine which adverse event terms refer to actual adverse events as opposed to symptoms of the illness itself, given that those terms may be identical? Is this new drug treating arrhythmias or causing them, for example?
Read -

The benefits of centralizing ontology management
Ontologies have become a key piece of infrastructure for organisations as they look to manage their metadata to improve the reusability and findability of their data. This is the first blog in our blog series 'Ontologies with SciBite'. Follow the blog series to learn how we've addressed the challenges associated with both consuming and developing ontologies.
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.