Introduction
Scientists are increasingly confronted with large volumes of data from multiple sources and different formats, the vast majority of which is in the form of unstructured text. While smart search engines are a ubiquitous feature of modern life, they lack the domain knowledge to be able to answer common research questions. To address this problem, SciBite has combined intelligent search features with our powerful standards-based semantic platform to create SciBite Search.
SciBite Search brings intelligent scientific search to everyone. Its modern, easy-to-use interface combines access to powerful domain-specific ontologies and AI-powered search capabilities. This enables scientists to quickly find the answers they need while also providing sophisticated text-mining capabilities for deeper, more exploratory queries.
Utilizing our robust suite of ontologies, SciBite Search automates semantic enrichment and annotation, transforming unstructured scientific text into clean, contextualised data which is Findable, Accessible, Interoperable and Reusable (FAIR) for individual teams or across the entire enterprise. It enables users to extract meaningful insights from both unstructured and structured information across:
- Public biomedical sources, such as MEDLINE, PubMed Central (PMC), and US ClinicalTrials.gov,
- Subscription content from providers such as Elsevier and others,
- Internal and external documents, such as Word documents, PowerPoint presentations and PDFs.
SciBite Search is simple to deploy and easy for departments to upload their own documents whilst ensuring access to proprietary information is controlled appropriately.
The evolution of search
The limitations of keyword searches
Most search applications are limited to text and keyword searches and lack the scientific intelligence needed to answer common research questions. For example, a keyword search for the drug Fingolimod would miss references to synonyms such as FTY-720, or its brand name, Gilenya.

Figure 1: Most search tools miss synonyms of search terms
This challenge is at the heart of the FAIR Data Principles, which aim to promote the integrity and re-use of scientific data.
Semantic search
At the core of SciBite Search is a smart index, created using our Named Entity Recognition (NER) engine, TERMite, which can process over 1000 MEDLINE abstracts per second, and our scientific vocabularies, or VOCabs, with over 20 million expertly curated scientific terms and their synonyms.
SciBite’s team of experienced ontologists create and maintain VOCabs by augmenting public ontologies using a combination of manual and machine curation to ensure quality, accuracy and comprehensive synonym coverage. Using these VOCabs, TERMite rapidly processes all ingested content and applies an explicit, unique meaning and description to scientific terms and concepts found within the text, contextualizing them so that they can be understood as “things, not strings“. This ensures that all relevant data will be found, regardless of which synonym is used as the search term.
SciBite Search also tags documents with the scientific entities found by TERMite, making it easy for users to instantly get a feel for what it is about.
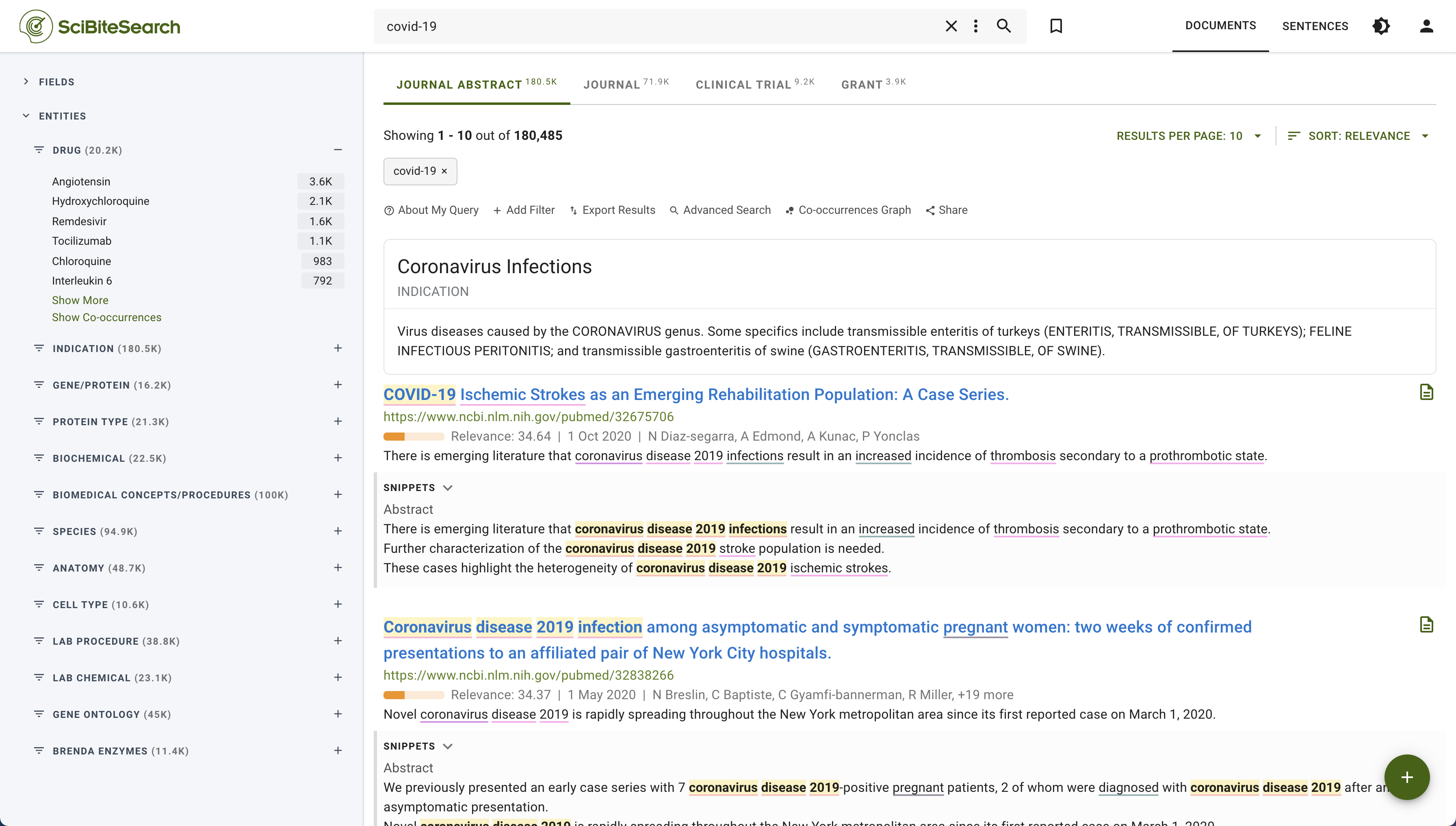
Figure 2: Leveraging identified concepts within documents for smart filtering (left-hand side of the screen)
This contextualisation afforded by semantic enrichment also enables users to answer more complex ontology-based questions and find all articles related to a specific topic e.g. all the scientific articles that talk about mode of action, all those that are about toxicology, etc. Another advantage of semantic search can be seen using the example with an article describing “Effect of Preventive and Curative Fingolimod Treatment Regimens on Microglia Activation and Disease Progression in a Rat Model of Multiple Sclerosis” which would be found by a simple text search using several of the terms in the sentence. However, SciBite Search understands, for example, that Fingolimod is an immunomodulatory drug and that multiple sclerosis is an autoimmune disorder. So, a simpler query for ‘immunomodulatory treatments for autoimmune conditions’ could be used which would return that article.
Augmented search
Most document search tools will only know about a relationship, such as Viagra is made by Pfizer, if it is explicitly stated within a document. SciBite Search builds upon its semantic search foundations using knowledge graphs to augment the search experience, enabling users to make connections between scientific concepts and find information based on relationships.
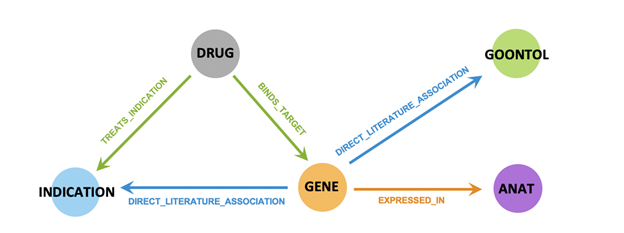
Figure 3: A visual representation of the connections that can be made using a Knowledge Graph
This makes it possible to ask questions and make inferences that cannot be made from any single data source and would otherwise remain unseen. For example, by augmenting semantically enriched scientific literature and data from the US ClinicalTrials.gov resource, SciBite Search will enable users to query for “Multiple Sclerosis fingolimod clinical trial locations in Germany”.
Deep learning
The addition of deep learning will further enhance the search experience. Firstly, deep learning enables modern search engines to reliably recognize why a user is asking something, otherwise known as ‘intent’ – SciBite Search will build upon this to enable scientists to use natural language scientific queries, surfacing powerful query capabilities while hiding the complex logic from end-users.
This ranges from questions that have a ‘yes/no’ answer to those that generate a set of facts and those that require aggregation of information, to such as:
- Is fingolimod an immunomodulatory drug?
- What are the known modulators of sphingosine-1-phosphate receptors?
- What is the top-mentioned drug for multiple sclerosis?
- What are the top 5 indications for fingolimod?
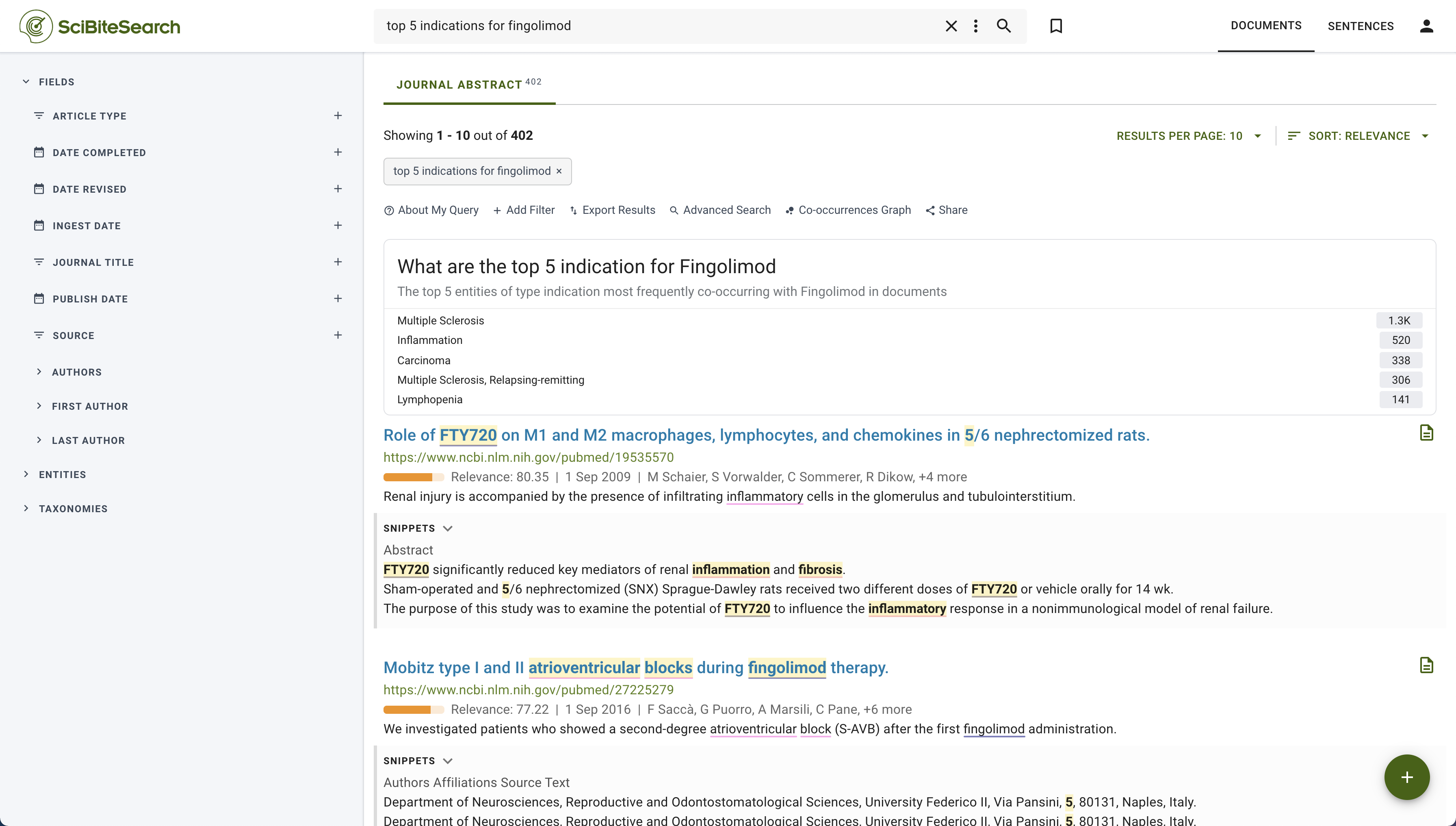
Figure 4: SciBite Search enables users to easily answer complex questions
Deep learning also enables users to explore complex, fuzzy relationships, such as “does fingolimod have any known side effects due to interactions with other drugs?”. Similarly, it enables accurate identification of relationships between entities based on the context in which they are mentioned.
Advanced search queries
SciBite Search offers powerful search capabilities with an intuitive user interface that allows researchers to quickly access the results they need, without the need to understand the complexities of the underlying data structures, or the functions required to surface them.
As well as improving the search experience for scientists, SciBite Search also provides powerful text mining capabilities to answer more complex questions, such as using an advanced search form or employing the SciBite Search Query Language (SSQL) to construct more sophisticated queries, using entities, types of entity, taxonomies, and plain text phrases.
Users can perform boolean queries and quickly navigate to the most interesting results based on taxonomies. SciBite Search supports both document and sentence-level searches and provides auto-complete and facet filtering to enable users to easily refine existing search results by field, entity, and taxonomies.
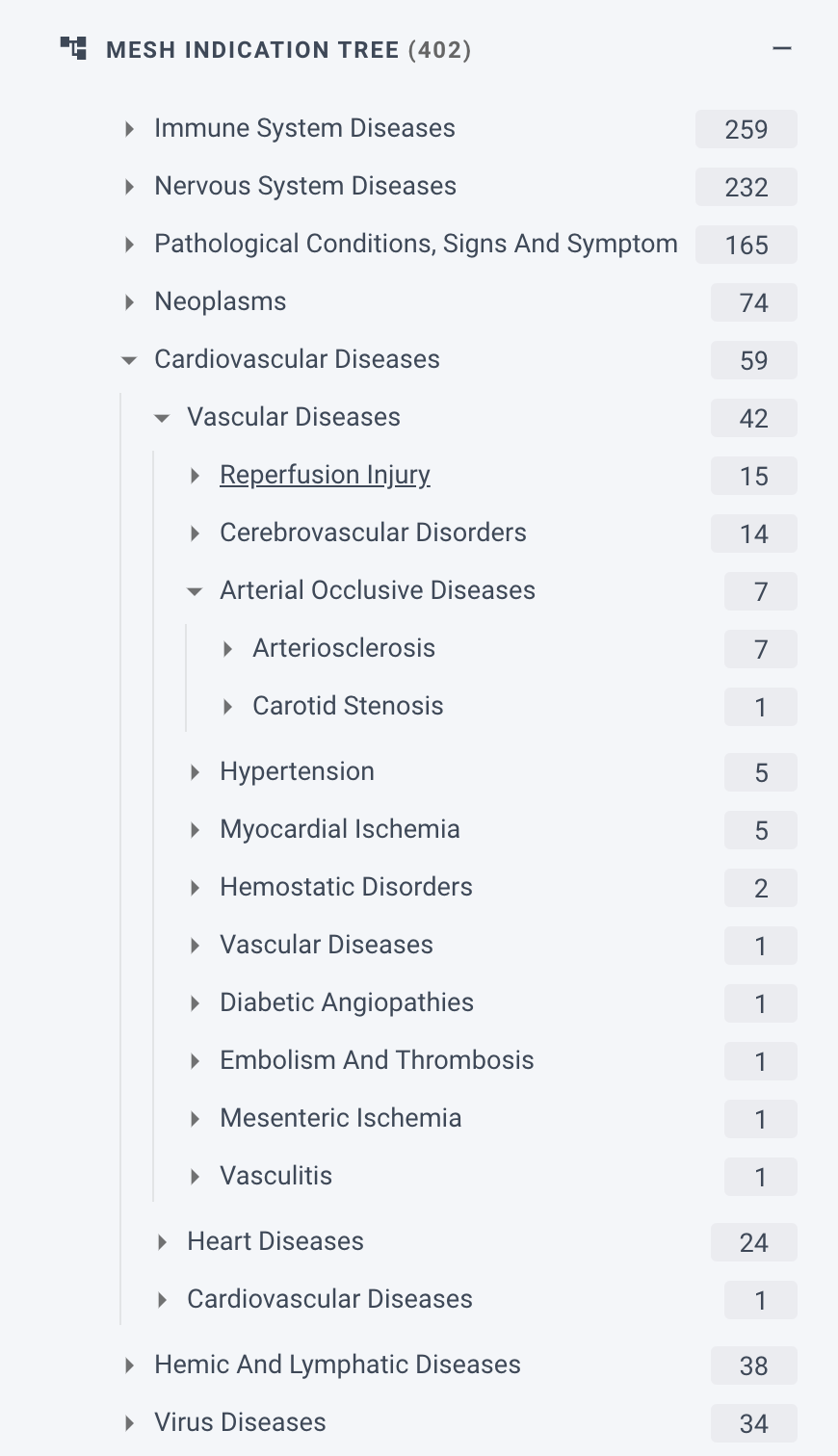
Figure 5: Facet filtering makes it easy to refine search results
Co-occurrence analysis enables users to instantly identify terms that co-occur with your original query. For example, by generating a list of genes that are mentioned most frequently with a disease of interest, potential new avenues for research can be revealed.
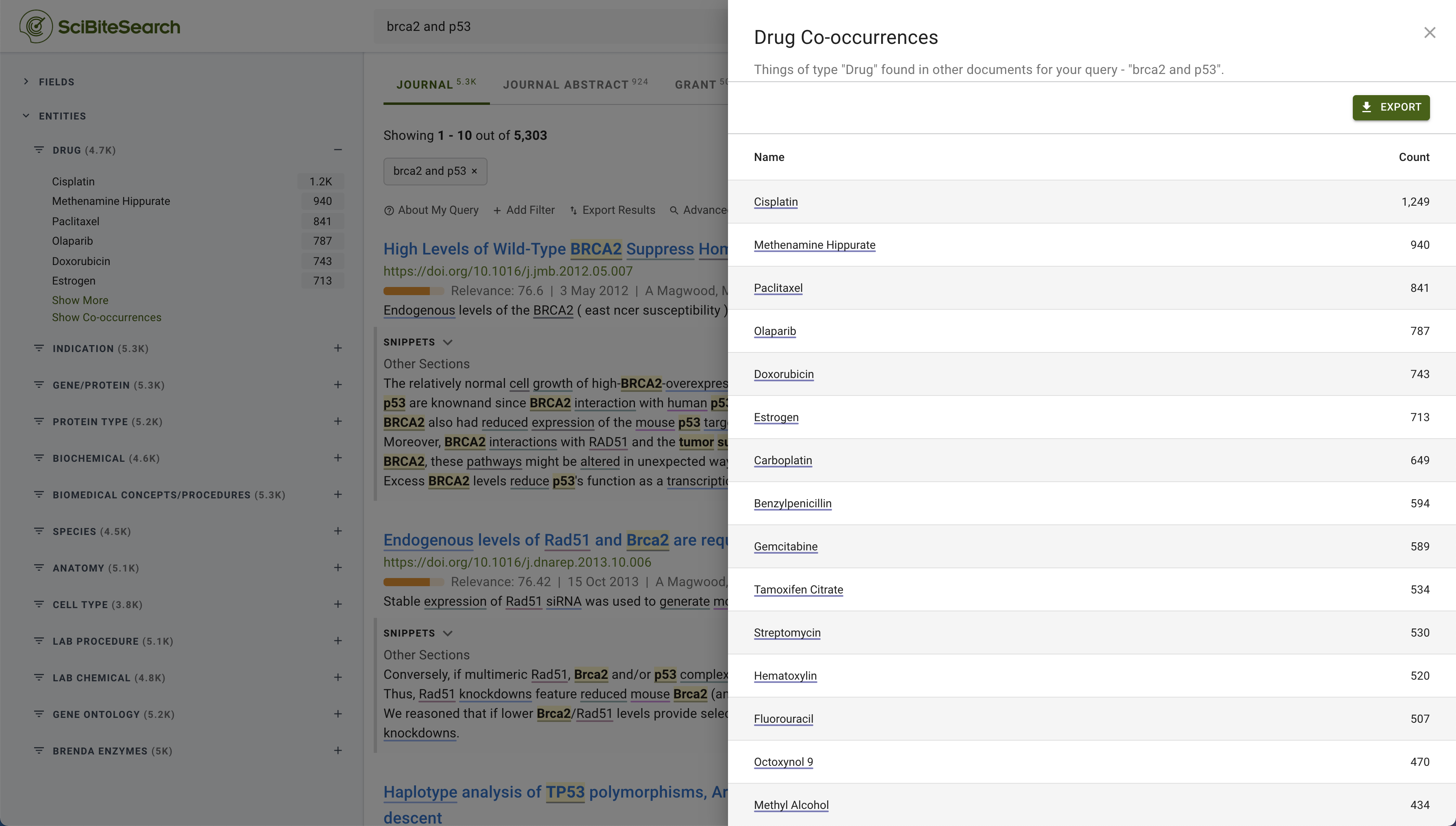
Figure 6: Co-occurrence analysis ranks the drugs that co-occur most often with a target of interest
Query across internal and external content
SciBite Search features federated search for both open-source and proprietary data. Full document-level security and role-based permissions allow administrators to control access to proprietary content at the departmental, group, or individual level.
Configurable domain-specific and generic connectors and parsers for different sources and content types make it simple to load and process content, including internal documents and data from key research systems, such as electronic laboratory notebooks (ELNs).
SciBite Search enables viewing semantic annotations on PDFs, making it easy for users to instantly get a feel for what a document is about whilst retaining its original layout and formatting.
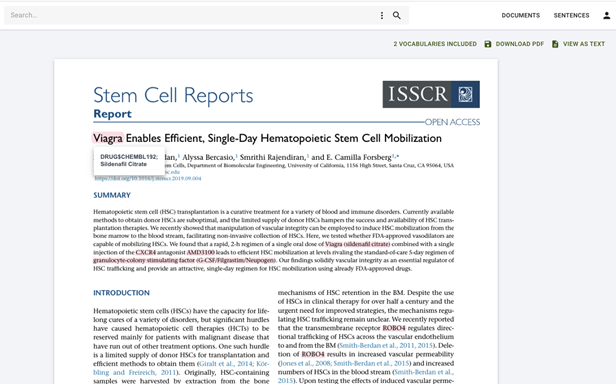
Figure 7: Summarising all Terms Identified within a document (left-hand side of the screen)
SciBite Search not only provides a better search experience for internal data, it also enables users to answer more complex questions, such as:
- Find all references to project ABC-101, regardless of the syntax used by the author (e.g. ABC-101, ABC101, and ABC 101)
- Find all experiments for a specific target across the organisation, regardless of which synonym was used by the author of the experiment.
- Which projects are investigating potential biological therapeutics?
- Which targets have we studied that are associated with inflammatory disorders?
- Which diseases have we studied for both a target of interest and other targets in the same class and what were the outcomes?
- Which pre-clinical studies have utilised a specified mouse model?
- Which experimental techniques are growing across the organisation and would benefit from a core facility?
SciBite Search supports a wide range of use cases, from discovery through to development, including:
- Unifying multiple data sources into a single solution for organization-wide search. For example, combining public biomedical literature, clinical trials, and grants with proprietary data to facilitate ‘one-stop-shop’ federated searches;
- Incorporating full-text biomedical literature from publishers to better address research needs. For example, the loading of licensed data from third-party publishers (e.g. Elsevier, Wiley, and Spring-Nature) or content brokers (e.g. the Copyright Clearance Centre);
- Producing bespoke project databases, controlling access, and interrogating internal document subsets. Users can limit the data other groups or partners can access.
Tailored to your needs
SciBite Search provides a suite of personalisation options to enable administrators and end-users to tailor the search experience for expert users and those who require less sophisticated functionality, as well as to cater to the specific analysis needs of individuals, departments, or other user groups. Options include adjustments to the display of results, data ingestion control, indexing, and search weighting.
Complete customisation and control:-
Enhance search results with vocabulary preferences:-
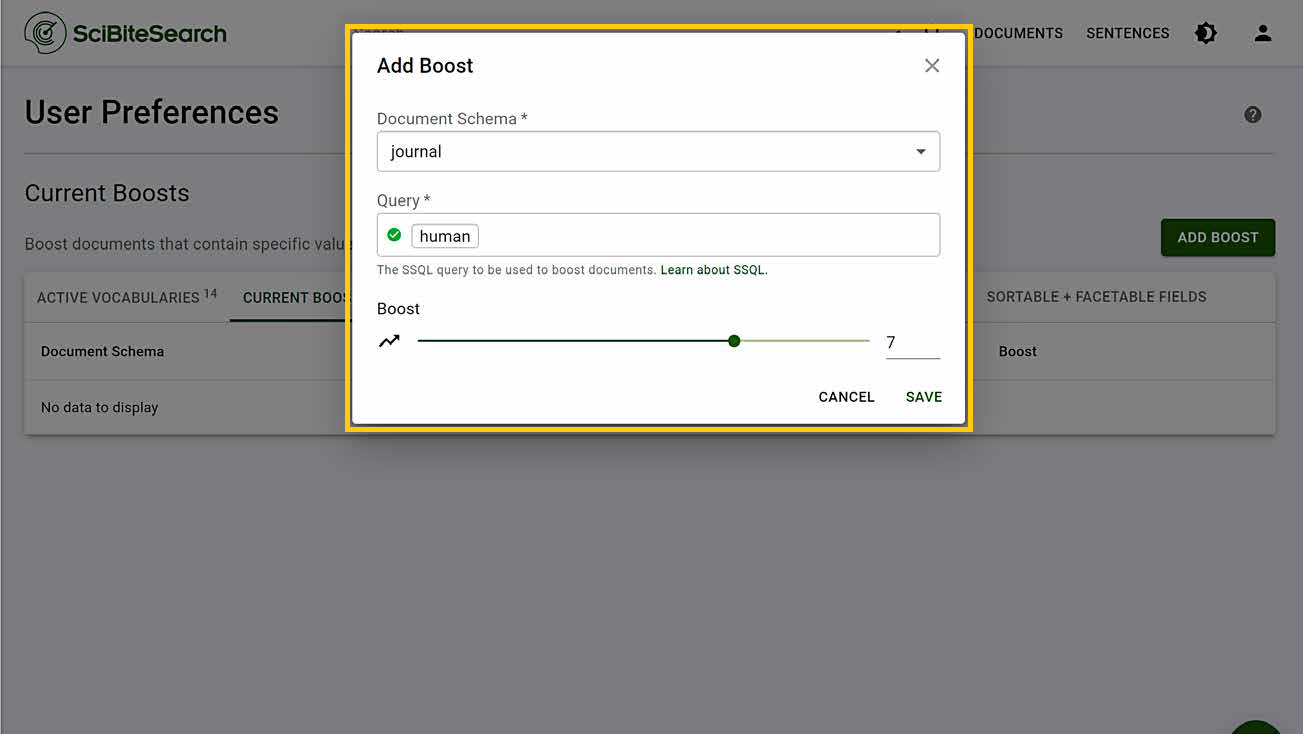
Tailor search results further with boosts:-
Additional integration options
SciBite Search can also be customized with internal branding, including user interface themes, colour schemes, and logos.
Following our ‘API-first’ philosophy, multiple RESTful APIs simplify integration into existing workflows and ecosystems.
The way ahead
The SciBite Search development roadmap will focus on several key areas with the objective of becoming the best biomedical research solution for your department or small enterprise.
This includes providing seamless access to additional insights, answers, and content sources together with more augmented search, question-answering capabilities, and connectors for both structured and unstructured data sources. We will also have deeper integration with SciBite’s CENtree ontology management solution so that customers can leverage our full ecosystem of tools.
About SciBite
SciBite is an award-winning semantic software company offering an ontology-led approach to transforming unstructured content into machine-readable clean data. Supporting the top 20 pharma with use cases across life sciences, SciBite empowers customers with a suite of fast, flexible, deployable API technologies, making it a critical component in scientific data-led strategies.
Contact us to find out how we can help you get more from your data.
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.