Unlocking patents as a data source in the Life Sciences
Throughout this blog we highlight some complexities that exist in extracting meaningful information from patents and show various solutions, making use of SciBite technology alone or, augmented by or delivered by our partners.

Overview of challenges and using semantic technology to overcome them
Filling a patent can be a double-edged sword, protecting the patent holder’s IP while at the same time disclosing the details of the discovery to the scientific community and competitors alike. With this in mind, patents are structured in such a way that makes extracting relevant information difficult. Patent content is intentionally obfuscated using ambiguous and broad language. Patents are often long documents containing lots of technical jargon in which new and previously undefined terms are prevalent. This is compounded by a lack of unified patent format, structure, and language.
Interpretation of patents can unlock a wealth of knowledge that can be utilized in the life sciences for use cases such as horizon scanning, competitive intelligence, and freedom to market, each with differing levels of complexity. Exploiting this information requires expert knowledge and/or advanced tools to streamline the exploration of such a vast set of data, both of which are very expensive.
Using semantic technology to extract knowledge from patent data
In this blog, we share how SciBite’s technology tools can address key challenges with knowledge extraction from patent data and showcase how they have been used by customers and partners alike for mining patents to extract scientific insight. The requirements of patent analysis vary depending on the types of information to be extracted and the questions to be answered, but typically they are used for market or business intelligence.
Overcoming the challenge of patent synonymity
When it comes to analyzing patent data, there are a number of specific challenges that SciBite’s technology can address. Synonymity, or using words with the same or equivalent meaning, makes search and analytics difficult. Our VOCabs provide extensive synonym support, and when used in conjunction with TERMite, our named entity recognition engine, specific entities can be tagged regardless of which synonym appears in the text. Once processed through TERMite, the patent can be searched in a semantically aware manner, returning search hits independent of which synonym is used. (Figure. 1)
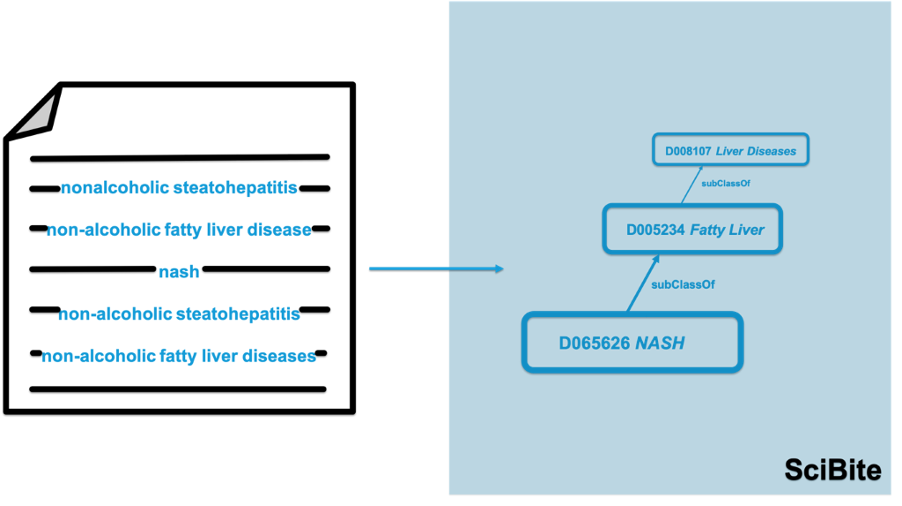
Figure 1. SciBite addresses the synonymity in life science data. Regardless of the synonym used to describe a specific indication in the literature, all instances are aligned to a single UID.
Overcoming the challenge of patent ambiguity
Another challenge is ambiguity when the same word or acronym has multiple meanings. Examples include Hedgehog, which could be a gene name or a species, or GSK, which could be GlaxoSmithKline or Glycogen Synthase Kinase. Additional contextual information is required to determine the correct meaning. We address ambiguity within TERMite by flagging ambiguous terms and utilizing additional rules to handle these. For example, if Hedgehog co-occurs with terms like “gene,” “expression,” and “upregulated” within close proximity, then it is much more likely the term refers to the gene rather than the species.
Once a patent is annotated with TERMite, it is important to consider which of the entities mentioned within that document are relevant to the patent, and which have been placed there for obfuscation purposes. To this end, we have a Patent Analyser Workflow, which considers various metrics, including the frequency and location of entities in the patent, to infer whether or not that entity is relevant to the key findings of the patent.
Furthermore, we also support the ability to extract associations from patent data. For example, one may wish to identify all drugs that may bind to a particular target, and so could search for a pattern that describes this association, such as DRUG-binds-GENE using our semantic pattern recognition tool, TExpress. These associations can then be utilized downstream, in various ways, such as providing a more accurate representation of context, or during an exercise in knowledge graph creation. Watch our webinar on Creating Knowledge Graphs from literature.
Patent analysis projects: Customer-built solutions
SciBite’s technology has been used to support various patent analysis projects, with and without partners, and to address use cases with varying levels of complexity.
Recently, SciBite supported a target prioritization project making use of patent data from the IFI CLAIMS database. Work in this project involved analyzing and prioritising a life-science-specific subset of IFI patents and building a graph database to explore relations from this content. The same set of patents was then served in DOCstore, our semantic search and analytics UI for further human analysis.
Wolfgang Thielemann, Head of Semantic & Knowledge Graph Technologies at Bayer, recently presented a patent analysis platform at SciBite’s User Group Meeting. As part of the solution, our technology was used to annotate millions of patents to be served internally for search and analytics purposes and is being deployed across the enterprise. TERMite and VOCabs were used to semantically enrich patent content, identifying key concepts such as targets, indications, and drugs and supporting Bayer’s life science innovation. Get in touch with the SciBite team to learn more.
Patent analysis projects: Out-of-the-box patent solutions
If you don’t have the resources or desire to build a custom patent analysis solution, then we offer a number of out-of-the-box solutions, either directly from SciBite or through our partners.
SciBite’s technology solutions are primarily aimed at scientific professionals rather than legal professionals and vary in patent coverage (geographical regions), patent formatting, complexity, and price. Content is served in DOCstore with varying source data and the degree of entity extraction that is performed. The cheapest solution serves patents from the European Patent Office (EPO), United States Patent and Trademark Office (USPTO), and World Intellectual Property Organisation (WO) content. A more comprehensive solution is the use of IFI’s CLAIMS patent database as a source of patent content, providing up-to-date and standardized patent content from more than 100 sources. If you already have a source of patent data, then SciBite can also utilise this.
The degree of analysis can vary depending on user requirements. Identification and tagging of basic entities using TERMite and VOCabs is a point of entry, through to a more complex solution based around TEXpress to identify complex entities and using the Patent Analyser Workflow to improve the accuracy of relevant entities.
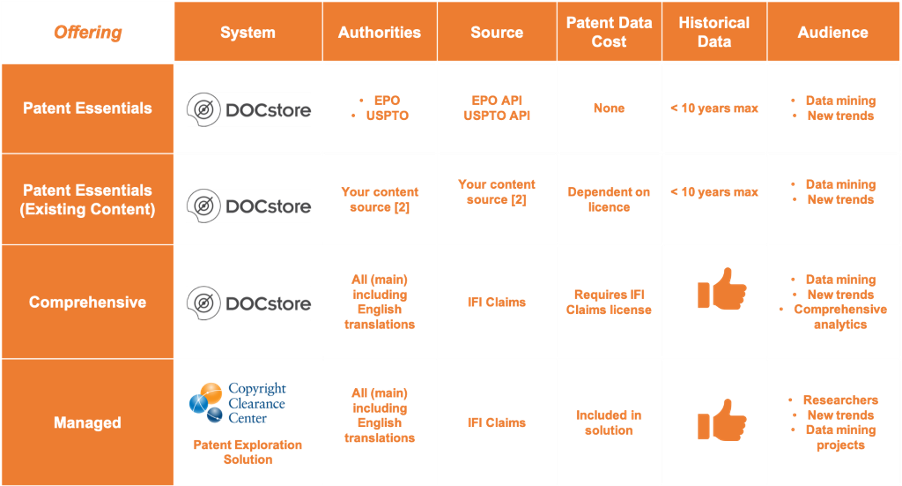
Table 1. SciBite offers pre-configured patent analysis solutions either directly or through our partners. SciBite offers a range of pre-configured patent analysis solutions. This table summarises the key differences between these different options.
Patent analysis solutions through SciBite’s partners
Through a partnership with SciBite, Copyright Clearance Center offers a preconfigured package called the Patent Exploration Solution. This cloud-based solution combines IFI’s global patent database, with SciBite’s TERMite and VOCabs to semantically enrich patent content which is subsequently presented in DOCstore. This solution enables scientific professionals to semantically search patent data from more than 70 sources and from more than 90 countries, without the need for extensive IT resources. Contact Copyright Clearance Center to learn more.
Through a partnership with Stardog, SciBite can also offer knowledge-graph-based solutions, whereby semantically enriched patent content can be served directly into Stardog’s knowledge graph platform for further analysis. Read our blog to learn more about how our semantic enrichment technology is being used to facilitate the production of Knowledge Graphs.
We’ve highlighted some complexities that exist in extracting meaningful information from patents and shown various solutions, making use of SciBite technology alone or, augmented by or delivered by our partners. Depending on the use case and end-user requirements, we can provide a tailored solution – with varying degrees of cost.
Contact the SciBite team to discuss or find out more about how we can help to extract knowledge from patent data.
Related articles
-

CCC launches RightFind Insight, transforming scientific research
Just released by the Copyright Clearance Center, a semantic search solution applied to full-text articles
Read -
SciBite partners with Copyright Clearance Center
We live in a world of increasing volumes, sources and formats of scientific content. So how can you find what is important quickly, simply, and with the confidence that you have missed nothing?
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.