Drug repurposing, rare diseases and semantic analytics
In this blog we cover how to look potentially reduce the cost of and speed up the repurposing pipeline.

Rare diseases affect around 6-7% of the population in the developed world (defined as fewer than 1 in 2,000 in Europe and fewer than 200,000 individuals in the US).
By their very definition of serving a relatively small population of people, the cost of developing brand new drugs for this audience (or orphan drugs) can be prohibitively expensive – yet legislation in the U.S. (FDA Orphan Drug Act, 1983), Japan, Australia and Europe incentivises treatment development.
So what’s a pharmaceutical company to do? Is there a more cost-effective way to reach cures faster?
Enter drug repurposing.
On the surface, drug repurposing promises much – known safety profiles of existing drugs, a reduced development timeline and as a result, a significantly reduced cost to market (we’re talking bringing expenditure down from billions of dollars to millions of dollars here).
There’s still a large amount of research to trawl through, a time-consuming and resource-heavy task. This is why drug companies are currently focusing on automated literature analysis.
Let’s look at the example of Arteriovenous Malformation (AVM), which has been in the news here recently in the UK. It’s a condition which affects hundreds of thousands of people across the world, causing abnormalities in blood vessels. These abnormalities can result in dangerous complications and disfigurements. Now, researchers have identified drugs which could target the underlying cause of the condition.
Take a look at this diagram which simplifies the repurposing pipeline from this piece of research.
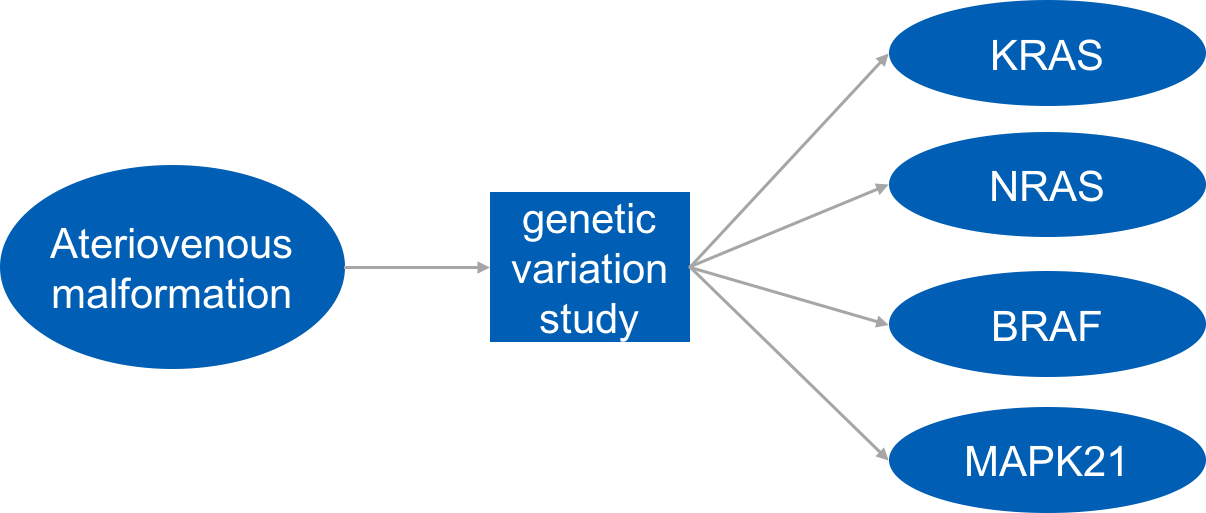
A simplified repurposing pipeline https://www.jci.org/articles/view/98589
Once these genes were identified, the next step in this particular repurposing study was to screen for drugs that targeted the relevant proteins. In this case there were a number of candidate drugs that were already used in cancer therapy.
Here, the disease in question has been taken as the starting point and faulty genes which have been identified on the RAS/MAPK pathway, which controls cell growth.
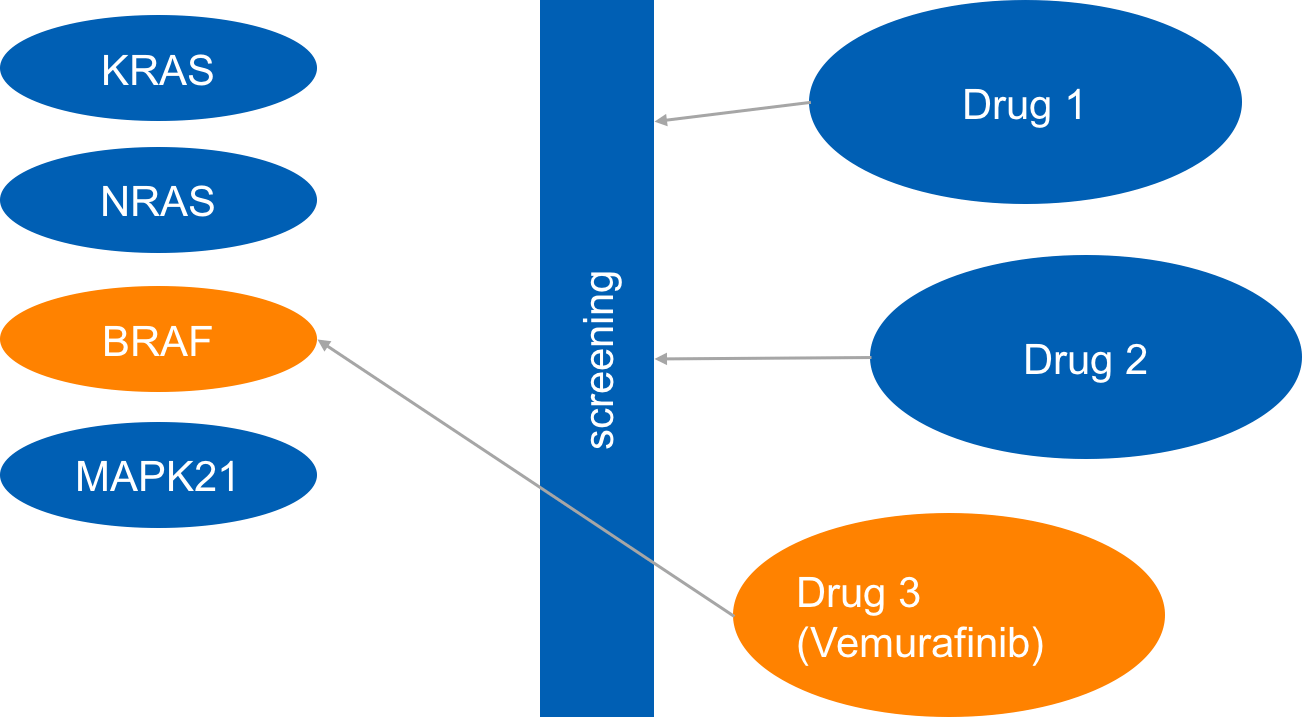
A simplified repurposing pipeline part 2
In this case, we see that in the treatment of AVM-BRAF mutant zebrafish with the BRAF inhibitor, Vemurafinib, restored blood flow in AVM.
How could semantic analytics play a part?
Drug repurposing relies on making connections, but as mentioned earlier, this is not easy when you’re faced with millions of documents, all with unstructured text.
Semantic annotation
Wouldn’t it be helpful if a computer could recognise key scientific information in unstructured text, such as scientific papers? Of course, the answer is yes, but one of the main hurdles with this approach is getting the computer to do this quickly, whilst being able to process scientific synonyms and ambiguity.
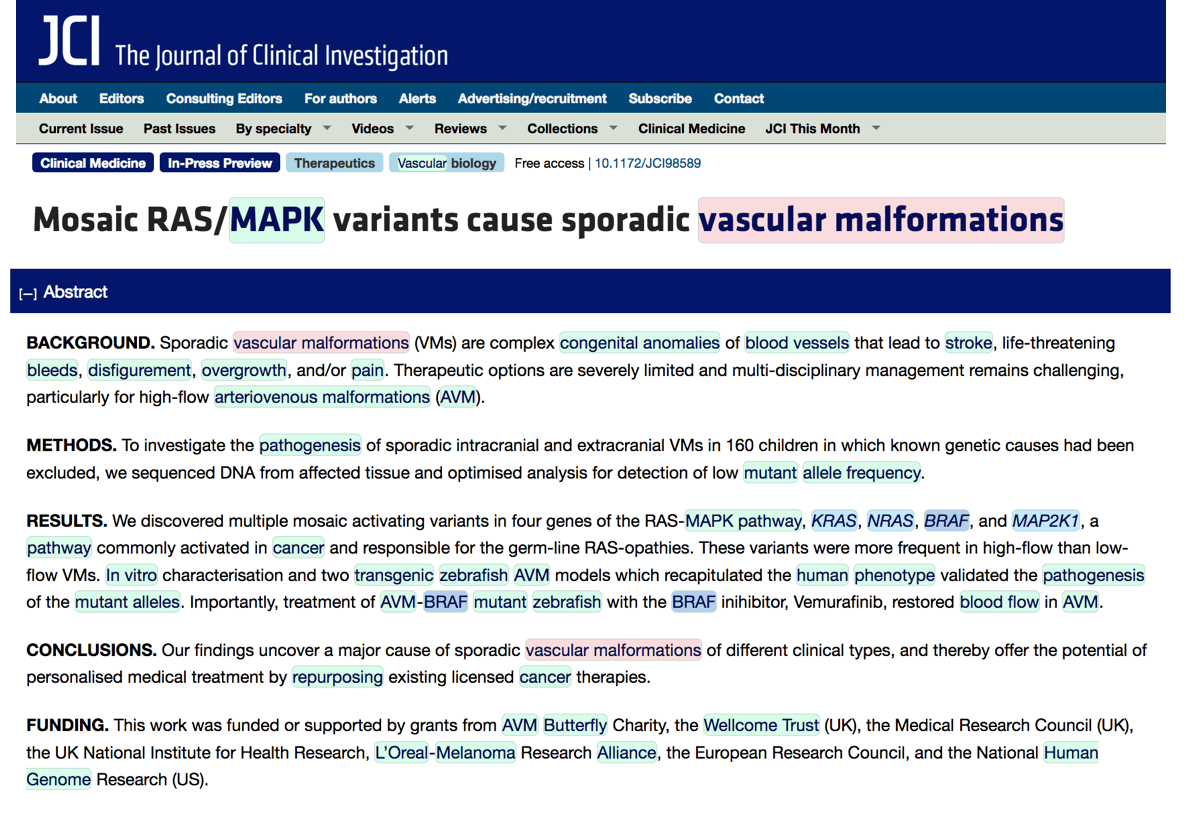
Al-Olabi et al, 2018: https://www.jci.org/articles/view/98589
Semantic search
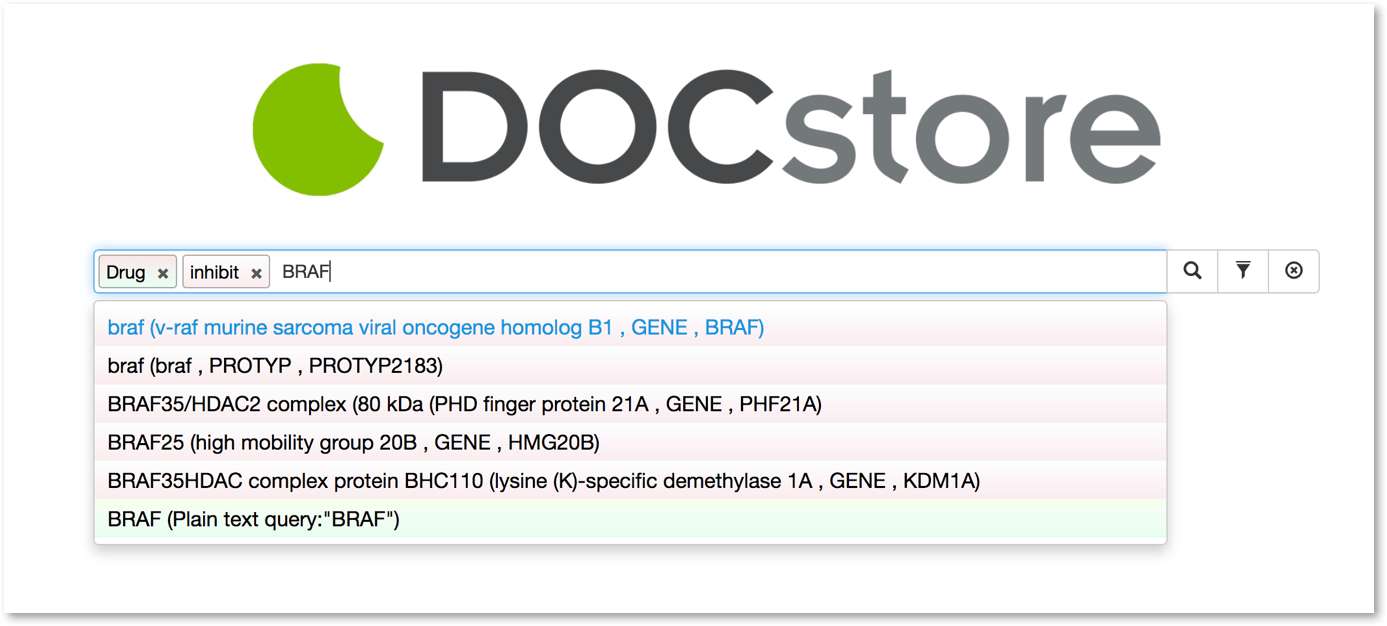
SciBite’s DOCstore in action
Building on this is semantic search. A tool which allows a researcher to find relevant information about their target. In this case, we’re looking for drugs that inhibit BRAF. As you can see, the search tool also picks up synonyms, ensuring that you don’t miss out on potentially valuable data. Contrast this with a conventional search engine, where if you search for “drug”, you’ll get results which mention the word “drug”. However, with a semantically enriched search engine, the computer knows that this actually means anything which is defined as a drug.
Extracting associations

And the results go beyond just highlighting individual entities, allowing you to extract information about relationships between entities, such as gene-phenotype or drug-target. Extrapolate this over 28 million Medline abstracts, and you have an incredibly powerful tool.
Building a knowledge network
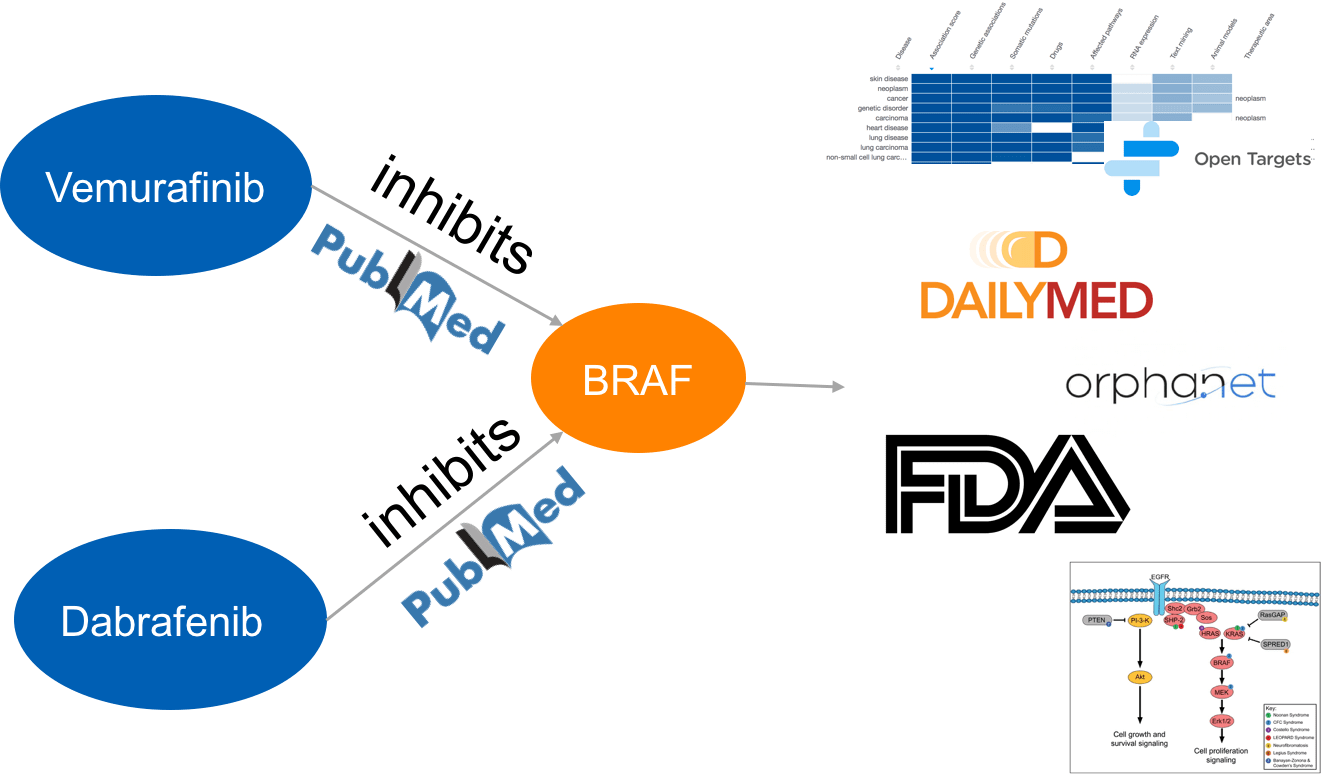
Image: Lopez-Pajares V et al 2013
These relationships can then be built into networks, providing you with a computer readable framework for searching the data and making new connections.
Labelling the entities in the text with unique identifiers allows you to take this a step further and map to other data systems, connecting related diseases, adverse events, pathways, drug labels.
And of course, this method can be turned on its head to discover new information. For example, you could compare diseases based on their phenotype profiles. Once you know that two diseases are strongly related, if there’s a drug which treats one of these conditions, you can hypothesise that you have a potential repurposing candidate on your hands for the other condition. This is a technique we’ve explored before in our blog post, Disease Detective Part 2: Exploring mechanistically-related diseases through shared phenotypic profiles.
If you’d like to know more about semantic analytics in drug repurposing, we’ve explored this theme in much more detail in our whitepaper. Download our whitepaper on Semantic Analytics: A Systematic, Data-Driven Approach to Drug Repositioning.
If you’d like to discuss with us how the SciBite Platform can transform your data, we’d love to hear from you on [email protected].
Related articles
-

A hacker’s guide to understanding bio-ontology jargon
Perfect for those new to bio-ontologies or who work with ontologists - a whole new vocabulary deciphered!
Read -

SciBite announces the release of SciBite Search 2.0


In this blog we announce the v2.0 release of SciBite Search, our intelligent scientific search platform. We’ve expanded our Elsevier data connectivity, broadening the sources you can load and search, as well as a host of features that improve the user experience.
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.