More than FAIR: Unlocking the value of your bioassay data
Bioassays are crucial in helping pharmaceutical companies determine the potency (biological activity) of their products, However, due to their complex nature, bioassays are among of the most challenging experiments to perform reliably and with accurate results.
Databases dedicated to managing bioassay data contain a wealth of research and development knowledge, but hurdles exist when it comes to extracting knowledge from these resources.
Many companies deploy data management systems that are geared towards entering rather than mining data. In addition, replacing such systems over time results in silos of legacy data in a variety of formats and aligned to different standards.
Data normalization and alignment
Bioassay data management systems are typically based on relational databases. While this affords some structure to the data, front-end applications tend to capture data as free text fields to avoid burdening or restricting users.
Even for defined entries, the meaning of a field or its contents may be ambiguous, imprecise or contain multiple different data types such as Gene, Target and Species.
The inconsistent use of synonyms during data entry may also make it difficult to collate data for a disease or target of interest. For example, searching a bioassay database for the Alzheimer’s related gene, PSEN1, would miss references to synonyms such as Presenilin-1, AD3 and PSNL1.
The normalization of literature and alignment of text to ontologies and industry standards is a vital part of the process as illustrated below.
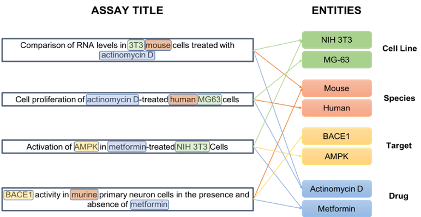
The above diagram shows the normalisation of entities captured in unstructured bioassay titles: extracting the Cell Line, Drug, Species and Target entities results in a semantic index that allows users to make connections between different bioassays.
Vendor independence
When applying standard ontologies and vocabularies to bioassay data, the source of these ontologies is a key consideration if an organisation is to avoid relying on specific vendors.
By employing public standards such as BAO (BioAssay Ontology), ChEMBL (chemical entities), CLO (Cell Ontology) and EFO (Experimental Factor Ontology), the resulting enriched data is open and interoperable from system to system – something that is also crucial in creating FAIR data principals within the enterprise.
Combining ontology management and semantic enrichment
Implementing a change in the organization’s data management strategy should not be confined to legacy data. Prospective data capture should also be aligned to the same ontological standards to ensure seamless integration of historic and future data.
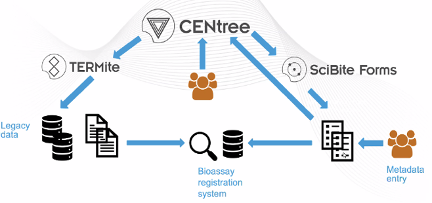
Below is a workflow that combines ontology management with semantic enrichment to unlock the value of bioassay data.
- Selection and management of relevant public ontologies using CENtree, SciBite’s ontology editing and management tool;
- Historic data normalization and alignment to the selected ontologies. For example, all synonyms and variations of the term “mouse” (mice, Mus musculus), will be aligned to the same term [Mus musculus] using TERMite, SciBite’s named entity recognition (NER) and extraction engine;
- Our form management tool, SciBite Forms, provides control over data input to ensure that entry terms are aligned to the correct class in the relevant ontology. SciBite Forms has autocomplete functionality to enable an organisation to achieve semantic enrichment of their data in real-time and at the point of capture. Rather than presenting users with restrictive and lengthy drop-down menus, SciBite Forms enables users to enter text into semantically aware fields and have the relevant terms suggested to them as they type.
This workflow also ensures that bioassay data and metadata conform to FAIR data principals by:-
- Creating identifiers that can be queried easily and intelligently (making it Findable);
- Allowing appropriate users computational access (making it Accessible);
- Ensuring data and metadata can be integrated with other sources (making it Interoperable);
- Creating data and metadata that is richly described and understandable, following community standards (making it Reusable).
Benefits of semantically enriched data
Enriching bioassay data not only makes it simpler to interrogate this data, it also allows more complex ontology-based questions to be asked. For example, it may be of interest to ask the following questions of your assay data:-
- Which targets have we studied that are associated with inflammatory disorders?
- Which diseases have we studied for both a target of interest and other targets in the same class and what were the outcomes?
- Which assays have utilised a rodent cell line?
- Which protein kinases have we run screens for (and how many screens have we done for each one)?
- Which experimental techniques are growing across the organisation and would benefit from a core facility?
Once data is normalized and aligned to ontologies, the task of enriching data with alternative sources (internal or external) becomes much simpler, allowing additional evidence to be integrated to automate and enrich the data analysis process.
The above use case combines retrospective and prospective data management, which has been deployed by a number of SciBite’s customers.
It brings intelligent scientific search to any bioassay platform, making bioassay data computationally accessible for automated analysis, ensuring realization of its full value.
Bioassay Registration use case
Data cleansing to unlock the potential of bioassay data
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.